
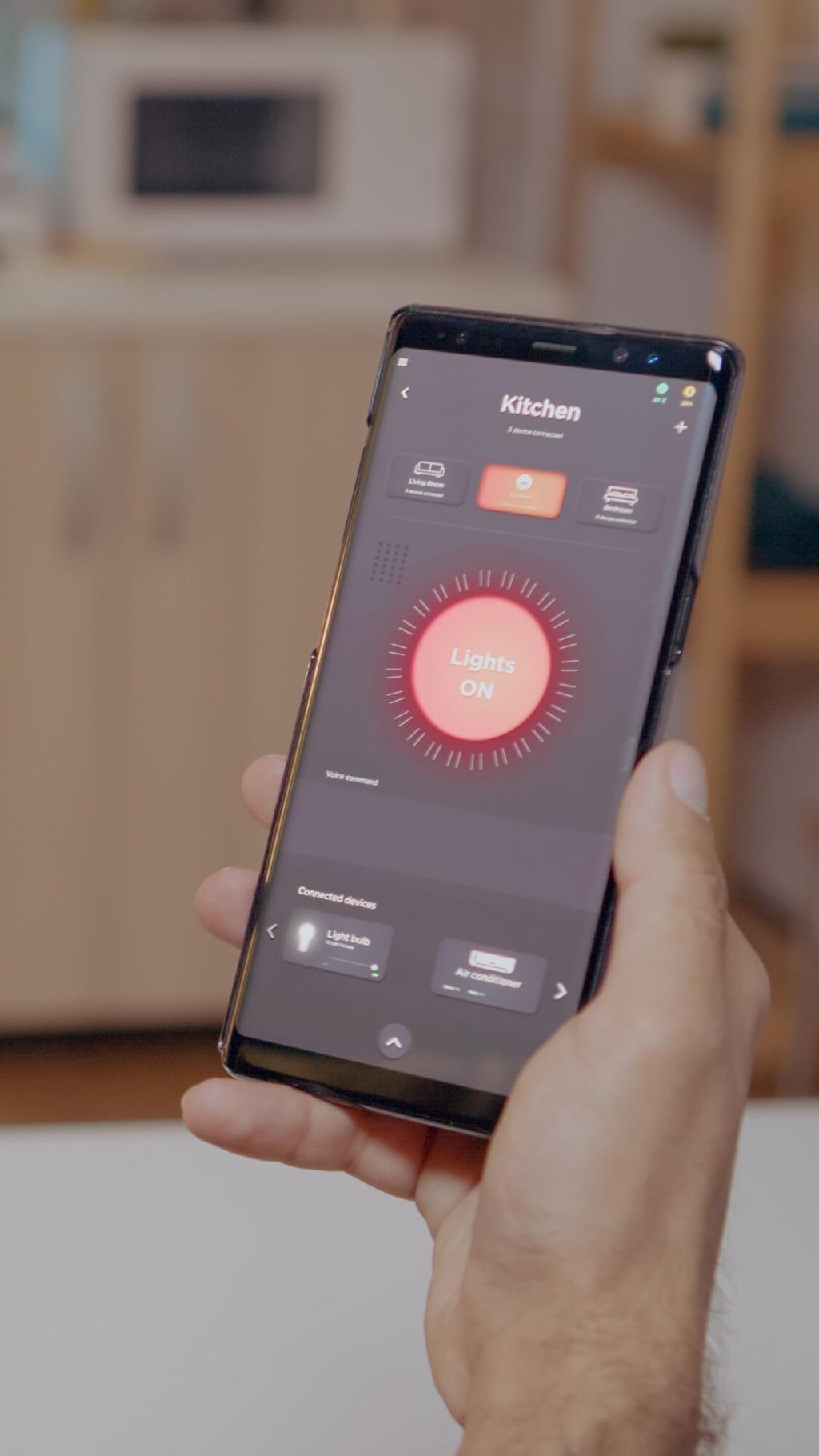

Testing That Actually Fights Crashes
Simulate slow networks, corrupted payloads, and intermittent permissions. Inject failures at boundaries like storage and sensors. A team once discovered their top crash by throttling GPS, revealing a race condition hidden behind optimistic assumptions about timing.
Testing That Actually Fights Crashes
Cover critical paths with fast unit tests, assert contracts at boundaries with integration tests, and verify flows with stable UI tests. Tag flaky tests aggressively and fix root causes. Reliability in CI mirrors reliability on user devices remarkably well.


